Take the high-paying essential deep learning nlp technology, this article is very thorough
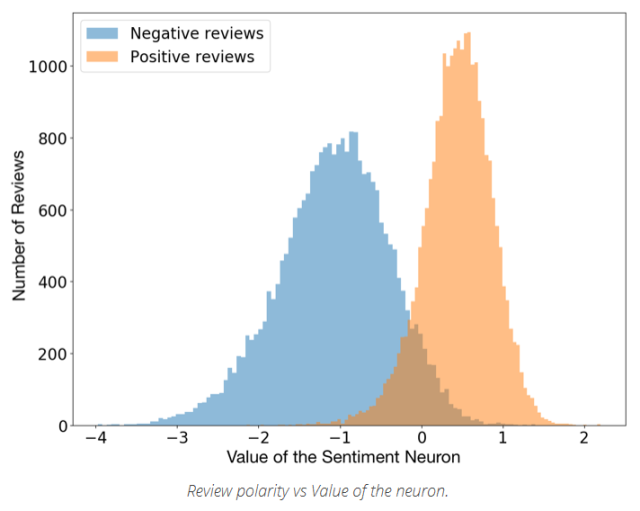
In the past few years, deep learning architectures and algorithms have made significant advances in areas such as image recognition and speech processing. In the field of NLP (Natural Language Processing), there was not much progress at first. But now, a series of advances in the NLP field have proven that deep learning techniques will make a significant contribution to natural language processing. Some common tasks such as entity naming recognition, word class tagging, and sentiment analysis, natural language processing can provide the latest results and go beyond traditional methods. In addition, in the field of machine translation, the progress made by deep learning technology should be the most significant. In this article, I will use a number of deep learning techniques to illustrate a series of advances in the NLP field in 2017 . There are many related scientific papers, frameworks and tools. I can't list them one by one here, and the content is not exhaustive. I just want to share with you and introduce a series of my favorite studies this year. I think that 2017 is an important year for deep learning. With the deep application of deep learning technology in the field of NLP and the surprising results, all the signs indicate that the NLP field will be assisted by deep learning technology. Continue to move forward efficiently. From training word2vec to using pre-trained models It can be said that Word embedding is the most significant technology of deep learning technology in the field of NLP. They followed the distributed hypothesis proposed by Harris (1954). According to this hypothesis, it is common to have a similar meaning in the context of context. For a detailed explanation of word embedding, you can also read Gabriel Mordecki's literature. Algorithms such as word2vec (Mikolov et al., 2013) and Glove (Pennington et al., 2014) have become representative algorithms in the NLP field. Although they cannot be considered as the application of deep learning techniques in this field (the shallow neural network is applied in word2vec, and Glove is an algorithm based on the counting model), the models they train are used as input to a large number of deep learning models. It is also a common way to combine deep learning techniques with natural language processing. Therefore, the current application of word embedding models in our field is often considered a good attempt. In the beginning, given an NLP problem that requires a word embedding model, we would prefer to train our own model in a large corpus related to the domain. Of course, this is not the best way to use the word embedding model, so you need to start slowly from the pre-training model. Through the training of Wikipedia, Twitter, Google News, web crawling and other data, these models can easily integrate the word embedding model into the deep learning algorithm. This year's research progress confirms that the pre-training word embedding model remains a key issue in the NLP field. For example, the fastText model from the Facebook AI Research (FAIR) lab, which publishes pre-trained model vectors in 294 languages, is a great job and a significant contribution to our field of study. In addition to the use of a large number of languages, the fastText uses character n-grams as semantic features, making the model a great application. In addition, the fastText model avoids OOV problems (beyond vocabulary issues) because even a very rare word (such as a domain-specific terminology) may share the same n-gram character with a common word. Therefore, in this sense, the fastText model performs better than the word2vec and Glove models, and has better performance for small databases. However, although we can see some progress in this area, there is still a long way to go in research in this area. For example, the well-known NLP framework spaCy integrates and applies word embedding models and deep learning models locally to NLP tasks such as NER and Dependency Parsing, and allows users to update models or use their own models. I think this is something that needs to be studied. In the future, for these NLP frameworks that are easy to apply to specific areas (such as biology, literature, economics, etc.), it is a very good way to pre-train the model. According to our situation, a series of fine-tuning optimizations are performed on the model in the simplest way to improve the performance of the model. At the same time, some methods for word embedding models are beginning to appear slowly. Adjust the generic embedded model to apply to a specific case Perhaps the biggest disadvantage of using pre-trained word embedding models is that there is a word distributional gap between the training data and the actual data used in our problem. Let's say, let's say you have research articles in biology, recipes, and economics. Since you may not have a large enough corpus to train a good performance word embedding model, you need a generic embedding model to help you improve your research. . But what if the generic embedded model can be adapted and applied to the specific case you need? The idea is simple and effective. Imagine that we know that the word embedding of the word w in the source domain is w_s. To calculate the embedding of w_t (target domain), the author adds a certain amount of transmission between the two domains to w_s. Basically, if the word appears frequently in both areas, it means that its semantics are not domain dependent. In this case, the word embedding trends generated in the two domains are similar due to the high amount of transmission. However, words in a particular field will appear more frequently in one area, and the amount of transmission required is small. The research topic on word embedding has not been widely studied and explored yet, but I think it will receive more attention in the near future. Emotional analysis will have an incredible effect This year, Ranford et al. found that individual neurons in the training model are highly predictive of emotional value. To further predict the next character in Amazon's comment text, they explored the characteristics of the byte-level circular language model. The results show that this single "emotional neuron" can indeed predict and classify comments as positive and negative. After noticing this behavior, they decided to test the model on the Stanford Sentiment Treebank database and found that the model was as accurate as 91.8%, compared to the previous model with an accuracy of 90.2%. This shows that models that are trained in an unsupervised manner with very few samples receive the most advanced sentiment analysis results on at least one specific but extensively studied database. Emotional neurons at work Since the performance of the model is based on character level, the neuron changes the state of each character in the text, which is quite amazing behavior. For example, after a word, the value of the neuron becomes a strong positive value, but this effect will disappear as the word disappears, which seems to make sense. Generate extremely biased text Of course, the trained model is still a valid build model, so it can be used to generate text similar to Amazon comments. However, I think it's great that you can choose to generate the polarity of the sample by simply overwriting the value of the emotional neurons. Text generation example (source - https://blog.openai.com/unsupervised-sentiment-neuron/) The NN model chosen by Krause et al. (2016) is a multiplicative LSTM model proposed by Krause et al. This is because they observed that the model's hyperparameter setting can converge faster than the normal LSTM model. It has 4096 neurons and is trained with 82 million Amazon's comment corpora. Why well-trained models accurately capture some of the open and fascinating problems in emotional concepts. At the same time, you can also try to train your own model and experiment. Of course, if you have plenty of time and GPUs, it will take a month to train this particular model with four NVIDIA Pasca GPUs. Sentiment analysis on Twitter Whether it's people's evaluation of corporate brands, analyzing the impact of marketing campaigns, or measuring the overall feelings of Hilary Clinton and Donald Trump during the last campaign, Twitter's sentiment analysis is a very powerful tool. SemEval 2017 Emotional analysis on Twitter has attracted the interest of NLP researchers and has received widespread attention in the political and social sciences. This is why the SemEval competition has presented a series of specific tasks since 2013. A total of 48 participating teams participated in the competition this year, showing great enthusiasm and interest. To give you a better idea of ​​what the SemEval game Twitter is launching (http://S17-2088), let's take a look at the five subtasks presented this year. Subtask A: Given a tweet to determine whether the expressed emotion is positive, negative or neutral. Subtask B: Given a tweet and a topic, express opinions on this topic in two cases: positive and negative. Subtask C: Given a tweet and a topic, there are five situations in which to express opinions on the topic: strong, weak, neutral, weakly affirmative, and powerful. Subtask D: Given a tweet about a topic, evaluate the distribution of tweets in the positive and negative categories. Subtask E: Given a set of tweets about a topic, evaluate the distribution of tweets in the five emotional categories: strong, weak, neutral, weak, and powerful. As you can see, subtask A is the most common task, with 38 teams participating in the assessment of this task, while others are more challenging. This year, 20 teams used Convolutional Neural Networks (CNN) and Long and Short Term Memory Network (LSTM) models. In addition, although the SVM model is still very popular, some teams have combined it with neural network methods or word embedding features. BB_twtr system This year I was amazed to discover that the BB_twtr system (Cliche, 2017) is a purely deep learning system and ranks first among the five sub-tasks in English. The author ensembles 10 CNN structures and 10 biLSTM structures, using different hyperparameters and pre-training strategies for training. To train these models, the authors used manually annotated tweets (given an order of magnitude, subtask A with 49,693) and built an unlabeled data set containing 100 million tweets. This data set is just Obtained by simply marking a tweet, such as a positive emoji indicating that the tweet content is :-), and a negative tweet for the content is the opposite expression. The lowercase, markup, URL, and emoji in these tweets are replaced with specific tags (, , etc.), and the contents of the characters are repeated. For example, "niiice" and "niiiiiiiice" become "niice". To pre-train word embedding information used as input to CNN and biLSTM structures, the author used word2vec, GloVe, and fastText (all using default settings) word vectors on unlabeled data sets. He then uses the distant dataset to refine the embedded features in order to increase the force information and then extract their features again using manually labeled data sets. Experiments with previous SemEval datasets show that using GloVe word vectors reduces performance and there is no single best model for all good data sets. The author then combines all models with a soft voting strategy. The resulting model results are better than the best historical results of the history of 2014 and 2016, and are very close to other years. Finally, it ranked first in the SemEval Dataset 5 subtask of the 2017 Natural Language Contest. Even a simple soft voting strategy adopted by this combination cannot be seen as an effective way, but this work demonstrates the possibility of combining deep learning models and an almost end-to-end approach (inputs must pass) Pretreatment). And it is beyond the monitoring method in Twitter's sentiment analysis. An exciting abstract summary system Automatic summarization, like automatic translation, is one of the earliest NLP tasks. There are currently two main methods: extraction-based methods, which are generalized by extracting the most important segments from the source text, while abstraction-based methods are constructed by generating text. From the perspective of development history, extraction-based methods are the most commonly used because they are simpler than abstraction-based methods. In the past few years, RNN-based models have achieved amazing results in text generation. They perform very well on short input and output text, but are often incoherent and repetitive for long text. In the work of Paulus et al., they proposed a new neural network model to overcome this limitation. The results are exciting, as shown below Generate a generalized model description (https://einstein.ai/research/your-tldr-by-an-ai-a-deep-reinforced-model-for-abstractive-summarization) The author used a biLSTM encoder to read the input and an LSTM decoder to produce the output. Their main contribution is a new intra-attention strategy that focuses on input and continuous output, and a new training that combines standard supervised word prediction and reinforcement learning. method. Internal attention strategy The purpose of the internal attention strategy is to avoid duplication in the output. To do this, they use temporal attention during decoding to see the input segments of the input text and then decide which next word to generate. This forces the model to use different parts of the input during the build process. They also allow the model to access the previously hidden state of the decoder. Then combine the two functions to choose the best next word for the output summary. Reinforcement learning In order to create a generalization that requires two different people to use different words and sentence sequences, these two summaries may be considered valid. Therefore, a good summary does not have to be as close as possible to the sequence of word sequences in the training data set. Knowing this, the authors did not use standard teacher-forcing algorithms to minimize the loss of each problem-solving step, but instead relied on reinforcement learning strategies and proved that this is a good choice. Almost the best result of the end-to-end model The model was tested on CNN and the Daily Mail dataset and achieved the most advanced results. In addition, a specific experimental result with a human evaluator also shows an increase in human readability and quality of the generated text. These results are admirable. The basic preprocessing of the model is: input text for word segmentation, lowercase letters, numbers replaced with "0", and then delete some specific entities in the data set. The first step in unsupervised machine translation? Bilingual dictionary induction, that is, using the source language and monolingual corpus of two languages ​​to identify the word translation pair, this is actually an ancient NLP task. Automated bilingual dictionaries help other NLP tasks such as information retrieval and statistical machine translation. However, most of these methods rely on a certain resource, usually an initial bilingual dictionary, but this dictionary is not always available or easy to set up. With the success of the word embedding method, the idea of ​​cross-language word embedding also appeared, with the goal of aligning the embedding space instead of the dictionary. Unfortunately, the first method also relies on bilingual dictionaries or parallel corpora. Conneau et al. (2018) proposed a very advanced method that does not depend on any particular resource and is excellent in three tasks: language translation of multiple language pairs, sentence translation retrieval and cross-language word similarity. Existing monitoring methods. The author developed a method of embedding the input two sets of words on the monolingual data for independent training to learn the mapping between them, so that the translated content is spatially close. They use the fastText word vector to train unsupervised word vectors on Wikipedia documents. The following images illustrate their core ideas: Establish a mapping between two words in the embedded space (https://arxiv.org/abs/1710.04087) The red X distribution is the embedding of English words, and the blue Y distribution is the distribution of Italian words. First, they used adversarial learning-https://en.wikipedia.org/wiki/Adversarial_machine_learning to learn the rotation matrix W. for the first original alignment. According to the ideas put forward by Goodfellow et al. in 2014, they mainly trained a generational confrontation network (GAN). To understand how GAN works, I recommend reading this article by Pablo Soto (https://tryolabs.com/blog/2016/12/06/major-advancements-deep-learning-2016/). To model the problem in terms of confrontational learning, they define the discriminator as a determined character, given some elements randomly sampled from WX and Y (see the second column in the figure above), each element representing a language . Then they train W to prevent the discriminator from making good predictions. This is very clever and elegant in my opinion, and the results directly are quite good. After that, they took two more steps to complete the mapping. The first step is to avoid noise introduced by rare words in the mapping calculation. Another step is to use the learned mapping and distance metrics to build the actual translation. In some cases the results are very good. For example, for the translation of words between English and Italian, in the case of P @ 10, they outperformed the best average accuracy by nearly 17%. Average accuracy of English-Italian word translation The authors claim that their approach can be seen as the first step towards unsupervised machine translation. We can take a look at how far this new promising approach can go. Specialized frameworks and tools There are many general-purpose DL frameworks and tools, such as the widely used Tensorflow, Keras and PYTorch. However, the DL framework and tools specific to the open source NLP direction have just emerged. This year is a great year for us because there are many useful open source frameworks already implemented in the community. There are three frameworks that draw my attention, and I think everyone will be very interested. Allen NLP The Allen NLP framework (http://allennlp.org/papers/AllenNLP_white_paper.pdf) is a platform built on PyTorch that was originally designed to be easier to use in the task of semantic NLP. Its purpose is to enable researchers to design and evaluate new models. It includes reference implementations of models in the Universal Semantic NLP task, including semantic role tags, text implicatures, and co-finger resolution. Parl AI The Parl AI framework (https://arxiv.org/pdf/1705.06476.pdf) is an open source software platform for conversational research. The platform is implemented in Python and is intended to provide a federated framework for sharing, training, and conversational model testing. ParlAI provides a very simple mechanism for merging with Amazon's Mechanical Turk. It also provides a very popular data set and supports several models, including neural models such as memory networks, seq2seq and LSTMs. Open NMT The OpenNMT toolset is a generic framework for sequence-to-sequence models. It can be used to perform machine translation, summarization, and image-to-text, speech recognition tasks. Ultimate thinking The steady growth in the use of DL technology in solving NLP problems is unquestionable. One of the most identifiable indicators is the change in the percentage of key NLP meetings used in deep learning papers over the past few years, such as ACL, EMNLP, EACL, and NAACL. Proportion of deep learning papers However, true end-to-end learning is just beginning. We are dealing with typical NLP tasks to prepare for data sets, such as cleanup, tokenization, or uniformity of some entities (eg, URLs, numbers, emails, etc.). We also use generic embedded. The downside is that they can't grasp the importance of keywords in special fields, and they perform poorly in multi-literal expressions. This is a key issue that I have repeatedly found in my work projects. This year is a very good year for deep learning applied to NLP. I hope that there will be more end-to-end learning books in 2018, and there will be more mature open source frameworks. You can share your thoughts and opinions on these works and frameworks in the comments section, and you are welcome to share the frameworks and books not mentioned in this article. Horizontal Capacitive Touch Display capacitive Touch Screen products,advertising display screens,query all-in-one monitors,widely used in our life.The Flat Panel Displays LCD advertising message information Activpanel release system is prepared by the company`s store owners in advance. Digital Signage Media Player digital signage for chromecast,digital signage for schools,digital signage media player,The Digital Signage Displays audience does not need to increase personal investment and consumption costs, but only needs to "focus on" resources. Flat Panel Displays media player for digital signage This is easy to accept for everyone. At this point, the popularization of advertising words on LCD screens is a kind of work that is profitable and has the characteristics of Interactive Flat Panel social development and Digital Signage Displays public welfare. capacitive touch display screen,20 points capacitive touch technology, widely used in different industries Jumei Video(Shenzhen)Co.,Ltd , https://www.jmsxdisplay.com